
- cross-posted to:
- technology@lemmy.ml
- cross-posted to:
- technology@lemmy.ml
Previous posts: https://programming.dev/post/3974121 and https://programming.dev/post/3974080
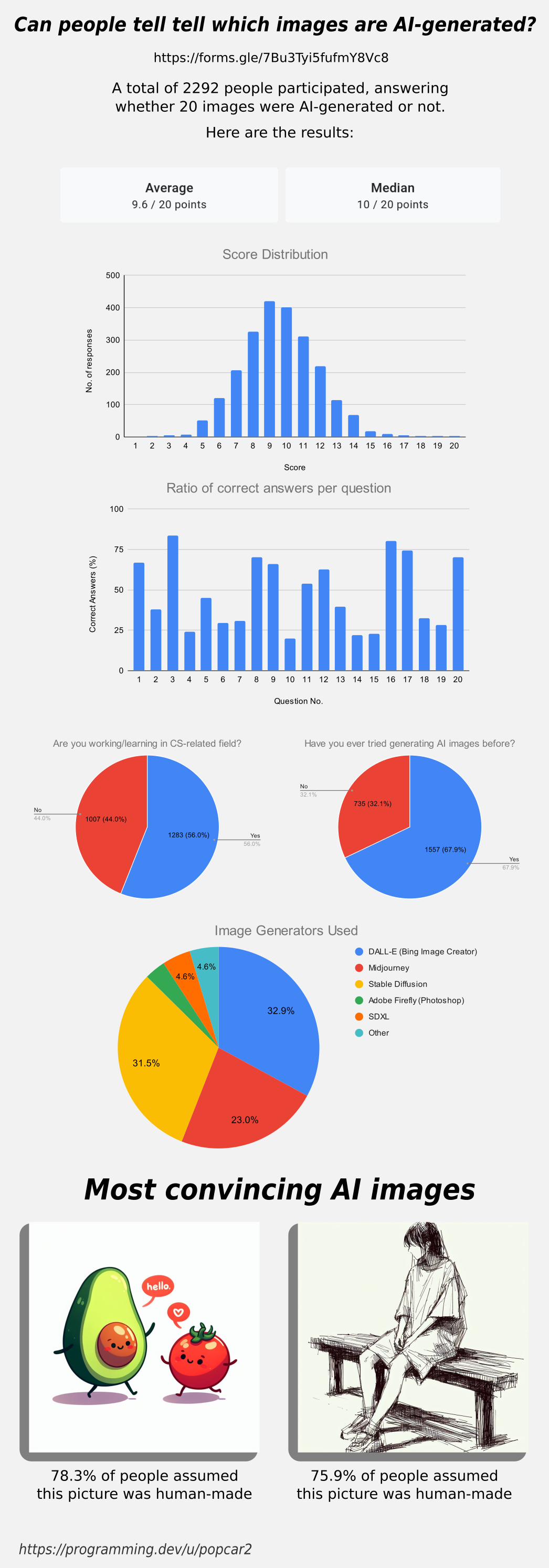
Original survey link: https://forms.gle/7Bu3Tyi5fufmY8Vc8
Thanks for all the answers, here are the results for the survey in case you were wondering how you did!
Edit: People working in CS or a related field have a 9.59 avg score while the people that aren’t have a 9.61 avg.
People that have used AI image generators before got a 9.70 avg, while people that haven’t have a 9.39 avg score.
Edit 2: The data has slightly changed! Over 1,000 people have submitted results since posting this image, check the dataset to see live results. Be aware that many people saw the image and comments before submitting, so they’ve gotten spoiled on some results, which may be leading to a higher average recently: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
You must log in or register to comment.
So if the average is roughly 10/20, that’s about the same as responding randomly each time, does that mean humans are completely unable to distinguish AI images?
In theory, yes. In practice, not necessarily.
I found that the images were not very representative of typical AI art styles I’ve seen in the wild. So not only would that render preexisting learned queues incorrect, it could actually turn them into obstacles to guessing correctly pushing the score down lower than random guessing (especially if the images in this test are not randomly chosen, but are instead actively chosen to dissimulate typical AI images).
I would also think it depends on what kinds of art you are familiar with. If you don’t know what normal pencil art looks like, how are ya supposed to recognize the AI version.
As an example, when I’m browsing certain, ah, nsfw art, I can recognize the AI ones no issue.
Agreed. For the image that was obviously an emulation of Guts from Berserk, the only reason I called it as AI generated was because his right eye was open. I don’t know enough about illustration in general, which led me to guess quite a few incorrect examples there.
I found the photos much easier, and I guessed each of those correctly just by looking for the sort of “melty” quality you get with most AI generated photos, along with intersected line continuity (e.g. an AI probably would have messed up this image where the railing overlaps the plant stems; the continuity made me accept it as real). But with illustrations, I don’t know nearly enough about composition and technique, so I can’t tell if a particular element is “supposed” to be there or not. I would like to say that the ones I correctly called as AI were still moderately informed because some of them had that sort of AI-generated color balance/bloom to them, but most of them were still just coin toss to me.
Maybe you didn’t recognize the AI images in the wild and assumed they were human made. It’s a survival bias; the bad AI pictures are easy to figure out, but we might be surrounded by them and would not even know.
Same as green screens in movies. It’s so prevalent we don’t see them, but we like to complain a lot about bad green screens. Every time you see a busy street there’s a 90+ % chance it’s a green screen. People just don’t recognize those.
Isn’t that called the toupee fallacy?
It is!!
Someone might assert that, “All toupees look fake. I’ve never seen a good toupee.” This is an example of neglecting the base rate because if I had seen good toupees, I wouldn’t know it.
Thanks, I love learning names for these things when they come up!
If you look at the ratios of each picture, you’ll notice that there are roughly two categories: hard and easy pictures. Based on information like this, OP could fine tune a more comprehensive questionnaire to include some photos that are clearly in between. I think it would be interesting to use this data to figure out what could make a picture easy or hard to identify correctly.
My guess is that a picture is easy if it has fingers or logical structures such as text, railways, buildings etc. while illustrations and drawings could be harder to identify correctly. Also, some natural structures such as coral, leaves and rocks could be difficult to identify correctly. When an AI makes mistakes in those areas, humans won’t notice them very easily.
The number of easy and hard pictures was roughly equal, which brings the mean and median values close to 10/20. If you want to bring that value up or down, just change the number of hard to identify pictures.
The number of easy and hard pictures was roughly equal, which brings the mean and median values close to 10/20.
This is true if “hard” means “it’s trying to get you to make the wrong answer” as opposed to “it’s so hard to tell, so I’m just going to guess.”
That’s a very important distinction. Hard wasn’t the clearest word for that use. I guess I should have called it something else such as deceptive or misleading. The idea is that some pictures got a below 50% ratio, which means that people were really bad at categorizing them correctly.
There were surprisingly few pictures that were close to 50%. Maybe it’s difficult to find pictures that make everyone guess randomly. There are always a few people who know what they’re doing because they generate pictures like this on a weekly basis. The answers will push that ratio higher.
A great example of the below 50% situation is the picture of the avocado and the tomato. I was confident that that was AI generated because I was pretty sure I’d seen that specific picture used as an example of how good Dall-E 3 was at normal text. However, most people who had used other models were probably used to butchered text and expected that one to be real.
If they did this quiz again with only pictures that were sketches, I bet the standard deviation would be much smaller.
It depends on if these were hand picked as the most convincing. If they were, this can’t be used a representative sample.
But you will always hand pick generated images. It’s not like you hit the generate button once and call it a day, you hit it dozens of times tweaking it until you get what you want. This is a perfectly representative sample.
As a personal example, this is what I generated and after like few hours of tweaking, regenerating and inpainting, this was the final result. And here’s another: initial generation, the progress animation, and end result.
Are they perfect, no, but the really obvious bad AI art comes from people who expect it to spit perfect images at you.
Personally, I’m not surprised. I thought a 3D dancing baby was real.
From this particular set, at least. Notice how people were better at guessing some particular images.
Stylized and painterly images seem particularly hard to differentiate.
One thing I’m not sure if it skews anything, but technically ai images are curated more than anything, you take a few prompts, throw it into a black box and spit out a couple, refine, throw it back in, and repeat. So I don’t know if its fair to say people are getting fooled by ai generated images rather than ai curated, which I feel like is an important distinction, these images were chosen because they look realistic
Well, it does say “AI Generated”, which is what they are.
All of the images in the survey were either generated by AI and then curated by humans, or they were generated by humans and then curated by humans.
I imagine that you could also train an AI to select which images to present to a group of test subjects. Then, you could do a survey that has AI generated images that were curated by an AI, and compare them to human generated images that were curated by an AI.
All of the images in the survey were either generated by AI and then curated by humans, or they were generated by humans and then curated by humans.
Unless they explained that to the participants, it defeats the point of the question.
When you ask if it’s “artist or AI”, you’re implying there was no artist input in the latter.
The question should have been “Did the artist use generative AI tools in this work or did they not”?
Every “AI generated” image you see online is curated like that. Yet none of them are called “artist using generative AI tools”.
But they were generated by AI. It’s a fair definition
I mean fair, I just think that kind of thing stretches the definition of “fooling people”
LLMs are never divorced from human interaction or curation. They are trained by people from the start, so personal curation seems like a weird caveat to get hung up on with this study. The AI is simply a tool that is being used by people to fool people.
To take it to another level on the artistic spectrum, you could get a talented artist to make pencil drawings to mimic oil paintings, then mix them in with actual oil paintings. Now ask a bunch of people which ones are the real oil paintings and record the results. The human interaction is what made the pencil look like an oil painting, but that doesn’t change the fact that the pencil generated drawings could fool people into thinking they were an oil painting.
AIs like the ones used in this study are artistic tools that require very little actual artistic talent to utilize, but just like any other artistic tool, they fundamentally need human interaction to operate.
But not all AI generated images can fool people the way this post suggests. In essence this study then has a huge selection bias, which just makes it unfit for drawing any kind of conclusion.
This is true. This is not a study, as I see it, it is just for fun.
Technically you’re right but the thing about AI image generators is that they make it really easy to mass-produce results. Each one I used in the survey took me only a few minutes, if that. Some images like the cat ones came out great in the first try. If someone wants to curate AI images, it takes little effort.
I think if you consider how people will use it in real life, where they would generate a bunch of images and then choose the one that looks best, this is a fair comparison. That being said, one advantage of this kind of survey is that it involves a lot of random, one-off images. Trying to create an entire gallery of images with a consistent style and no mistakes, or trying to generate something that follows a design spec is going to be much harder than generating a bunch of random images and asking whether or not they’re AI.
I think getting a good image from the AI generators is akin to people putting in effort and refining their art rather than putting a bunch of shapes on the page and calling it done
Did you not check for a correlation between profession and accuracy of guesses?
I have. Disappointingly there isn’t much difference, the people working in CS have a 9.59 avg while the people that aren’t have a 9.61 avg.
There is a difference in people that have used AI gen before. People that have got a 9.70 avg, while people that haven’t have a 9.39 avg score. I’ll update the post to add this.
deleted by creator
mean SD
No 9.40 2.27
Yes 9.74 2.30Definitely not statistically significant.
I would say so, but the sample size isn’t big enough to be sure of it.
So no. For a result to be “statistically significant” the calculated probability that it is the result of noise/randomness has to be below a given threshold. Few if any things will ever be “100% sure.”
Can we get the raw data set? / could you make it open? I have academic use for it.
Sure, but keep in mind this is a casual survey. Don’t take the results too seriously. Have fun: https://docs.google.com/spreadsheets/d/1MkuZG2MiGj-77PGkuCAM3Btb1_Lb4TFEx8tTZKiOoYI
Do give some credit if you can.
Of course! I’m going to find a way to integrate this dataset into a class I teach.
If I can be a bother, would you mind adding a tab that details which images were AI and which were not? It would make it more usable, people could recreate the values you have on Sheet1 J1;K20
Done, column B in the second sheet contains the answers (Yes are AI generated, No aren’t)
Awesome! Thanks very much.
I’d be curious to see the results broken down by image generator. For instance, how many of the Midjourney images were correctly flagged as AI generated? How does that compare to DALL-E? Are there any statistically significant differences between the different generators?
Are there any statistically significant differences between the different generators?
Every image was created by DALL-E 3 except for one. I honestly got lazy so there isn’t much data there. I would say DALL-E is much better in creating stylistic art but Midjourney is better at realism.
Sampling from Lemmy is going to severely skew the respondent population towards more technical people, even if their official profession is not technical.
If you do another one of these, I would like to see artist vs non-artist. If anything I feel like they would have the most experience with regular art, and thus most able to spot incongruency in AI art.
I don’t feel that’s true coming from more “traditional” art circles. From my anecdotal experience, most people can’t tell AI art from human art, especially digital and the kind the examples are from - meaning, hobbyist/semi-pro/pro deviant art type stuff. The examples seem obviously hand picked from both non-AI and AI-side to eliminate any differences as far as possible. And I feel both, the inability to tell the difference and the reason the dataset is what it is is because, well, they’re very similar, mainly because the whole deviant art/art station/whatever scene is a masssssive part of the dataset they use to train these Ai-models, closing the gap even further.
I’m even a bit of a stickler when it comes to using digital tools and prefer to work with pens and paints as far as possible, but I flunked out pretty bad, but then again I can’t really stand this deviant art type stuff so I’m not a 100% familiar, a lot of the human made ones look very AI.
I’d be interested in seeing the same, artist vs. non-artist survey, but honestly I feel it’s the people more familiar with specifically AI-generated art that can tell them apart the best. They literally specifically have to learn (if you’re good at it) to spot the weird little AI-specific details and oopsies to not make it look weird and in the uncanny valley.
I still don’t believe the avocado comic is one-shot AI-generated. Composited from multiple outputs, sure. But I have not once seen generative AI produce an image that includes properly rendered text like this.
Bing image creator uses the new DALL-E model which does hands and text pretty good.
generated this first try with the prompt a cartoon avocado holding a sign that says ‘help me’
People forget just how fast this tech is evolving
Absolutely SDXL with loras already can do a lot of what it was thought impossible.
Yeah Everytime iv seen anyone say “iv never seen it” makes it really obvious how little people actually know about the tech or follow it.
They basically saw it once a year ago and think it’s still the same.
Image generation tech has gone crazy over the past year and a half or so. At the speed it’s improving I wouldn’t rule out the possibility.
Here’s a paper from this year discussing text generation within images (it’s very possible these methods aren’t SOTA anymore – that’s how fast this field is moving): https://openaccess.thecvf.com/content/WACV2023/html/Rodriguez_OCR-VQGAN_Taming_Text-Within-Image_Generation_WACV_2023_paper.html
Yeah I’m sceptical too, what tool and prompt was used to produce this?
Its Dalle 3 its not that difficult to generate something like that using dalle 3 here’s some shreks I generated as a showcase Shrek 1 inage
All of these are just generated nothing else
Huh interesting it handles text relatively well
Its not that difficult to generate something like that using dalle 3 here’s some shreks I generated as a showcase Shrek 1 inage
All of these are just generated nothing else
Prompt and tool links? I know there are tools that try to pick out label text in the prompt and composite it after the fact, but I don’t consider this one-shot AI generated, even if it’s a single tool from the user’s perspective.
Its Dalle 3 like I said. As far as in aware Dalle 3 doesn’t do that since the text isn’t always perfect still. Can’t really provide prompts since its been a bit, and the history on it isn’t great, but I was just mostly shrek in x style and saying “x” do mind you Dalle is very heavily censored now, so you’re now unlikely to be able to recreate that.
It’s on - https://bing.com/create
I found the avocado comic the easiest to tell, since the missing eyebrow was so insanely out of place.
Something I’d be interested in is restricting the “Are you in computer science?” question to AI related fields, rather than the whole of CS, which is about as broad a field as social science. Neural networks are a tiny sliver of a tiny sliver
Especially depending on the nation or district a person lives in, where CS can have even broader implications like everything from IT Support to Engineering.
Wow, what a result. Slight right skew but almost normally distributed around the exact expected value for pure guessing.
Assuming there were 10 examples in each class anyway.
It would be really cool to follow up by giving some sort of training on how to tell, if indeed such training exists, then retest to see if people get better.
I feel like the images selected were pretty vague. Like if you have a picture of a stick man and ask if a human or computer drew it. Some styles aew just hard to tell
You could count the fingers but then again my preschooler would have drawn anywhere from 4 to 40.
I don’t remember any of the images having fingers to be honest. Assuming this is that recent one, one sketch had the fingers obscured and a few were landscapes.
Imo, 3,17,18 were obviously AI imo (based on what I’ve seen from AI art generators in the past*). But whatever original art those are based on, I’d probably also flag as obviously AI. The rest I was basically guessing at random. Especially the sketches.
*I never used AI generators myself, but I’ve seen others do it on stream. Curious how many others like me are raising the average for the “people that haven’t used AI image generators” before.
I’d be curious about 18, what makes it obviously generated for you? Out of the ones not shown in the result, I got most right but not this one.
The arm rest seamlessly and senselessly blends into the rest of the couch.
Thank you. I’m not sure how I’ve missed that.
Either the lighting’s wrong or you somehow have a zebra cat
Seen a lot of very similar pictures generated via midjourney. Mostly goats fused with the couch.
I was legitimately surprised by the man on a bench being human-made. His ankle is so thin! The woman in a bar/restaurant also surprised me because of her tiny finger.
I got a 17/20, which is awesome!
I’m angry because I could’ve gotten an 18/20 if I’d paid attention to the thispersondoesnotexists’ glasses, which in hindsight, are clearly all messed up.
I did guess that one human-created image was made by AI, “The End of the Journey”. I guessed that way because the horses had unspecific legs and no tails. And also, the back door of the cart they were pulling also looked funky. The sky looked weirdly detailed near the top of the image, and suddenly less detailed near the middle. And it had birds at the very corner of the image, which was weird. I did notice the cart has a step-up stool thing attached to the door, which is something an AI likely wouldn’t include. But I was unsure of that. In the end, I chose wrong.
It seems the best strategy really is to look at the image and ask two questions:
- what intricate details of this image are weird or strange?
- does this image have ideas indicate thought was put into them?
About the second bullet point, it was immediately clear to me the strawberry cat thing was human-made, because the waffle cone it was sitting in was shaped like a fish. That’s not really something an AI would understand is clever.
One the tomato and avocado one, the avocado was missing an eyebrow. And one of the leaves of the stem of the tomato didn’t connect correctly to the rest. Plus their shadows were identical and did not match the shadows they would’ve made had a human drawn them. If a human did the shadows, it would either be 2 perfect simplified circles, or include the avocado’s arm. The AI included the feet but not the arm. It was odd.
The anime sword guy’s armor suddenly diverged in style when compared to the left and right of the sword. It’s especially apparent in his skirt and the shoulder pads.
The sketch of the girl sitting on the bench also had a mistake: one of the back legs of the bench didn’t make sense. Her shoes were also very indistinct.
I’ve not had a lot of practice staring at AI images, so this result is cool!
does this image have ideas indicate thought was put into them?
I got fooled by the bright mountain one. I assumed it was just generic art vomit a la Kinkade
Yes, "the end of the journey’ got me too. So AI-looking. It’s this one:
https://www.deviantart.com/davidevart/art/The-End-Of-The-Journey-952592148
About the second bullet point, it was immediately clear to me the strawberry cat thing was human-made, because the waffle cone it was sitting in was shaped like a fish. That’s not really something an AI would understand is clever.
It’s a Taiyaki cone, something that already exists. Wouldn’t be too hard to get AI to replicate it, probably.
I personally thought the stuff hanging on the side was oddly placed and got fooled by it.
One thing I’d be interested in is getting a self assessment from each person regarding how good they believe themselves to have been at picking out the fakes.
I already see online comments constantly claiming that they can “totally tell” when an image is AI or a comment was chatGPT, but I suspect that confirmation bias plays a big part than most people suspect in how much they trust a source (the classic “if I agree with it, it’s true, if I don’t, then it’s a bot/shill/idiot”)
With the majority being in CS fields and having used ai image generation before they likely would be better at picking out than the average person
You’d think, but according to OP they were basically the same, slightly worse actually, which is interesting
The ones using image generation did slightly better
I was more commenting it to point out that it’s not necessary to find that person who can totally tell because they can’t
Even when you know what you are looking for, you are basically pixel hunting for artifacts or other signs that show it’s AI without the image actually looking fake, e.g. the avocado one was easy to tell, as ever since DALLE1 avocado related things have been used as test images, the https://thispersondoesnotexist.com/ one was obvious due to how it was framed and some of the landscapes had that noise-vegetation-look that AI images tend to have. But none of the images look fake just by themselves, if you didn’t specifically look for AI artifacts, it would be impossible to tell the difference or even notice that there is anything wrong with the image to begin with.
Right? A self-assessed skill which is never tested is a funny thing anyways. It boils down to “I believe I’m good at it because I believe my belief is correct”. Which in itself is shady, but then there are also incentives that people rather believe to be good, and those who don’t probably rather don’t speak up that much. Personally, I believe people lack the competence to make statements like these with any significant meaning.
And this is why AI detector software is probably impossible.
Just about everything we make computers do is something we’re also capable of; slower, yes, and probably less accurately or with some other downside, but we can do it. We at least know how. We can’t program software or train neutral networks to do something that we have no idea how to do.
If this problem is ever solved, it’s probably going to require a whole new form of software engineering.
And this is why AI detector software is probably impossible.
What exactly is “this”?
Just about everything we make computers do is something we’re also capable of; slower, yes, and probably less accurately or with some other downside, but we can do it. We at least know how.
There are things computers can do better than humans, like memorizing, or precision (also both combined). For all the rest, while I agree in theory we could be on par, in practice it matters a lot that things happen in reality. There often is only a finite window to analyze and react and if you’re slower, it’s as good as if you knew nothing. Being good / being able to do something often means doing it in time.
We can’t program software or train neutral networks to do something that we have no idea how to do.
Machine learning does that. We don’t know how all these layers and neurons work, we could not build the network from scratch. We cannot engineer/build/create the correct weights, but we can approach them in training.
Also look at Generative Adversarial Networks (GANs). The adversarial part is literally to train a network to detect bad AI generated output, and tweak the generative part based on that error to produce better output, rinse and repeat. Note this by definition includes a (specific) AI detector software, it requires it to work.
What exactly is “this”?
The results of this survey showing that humans are no better than a coin flip.
while I agree in theory we could be on par, in practice it matters a lot that things happen in reality.
I didn’t say “on par.” I said we know how. I didn’t say we were capable, but we know how it would be done. With AI detection, we have no idea how it would be done.
Machine learning does that.
No it doesn’t. It speedruns the tedious parts of writing algorithms, but we still need to be able to compose the problem and tell the network what an acceptable solution would be.
Also look at Generative Adversarial Networks (GANs). […] this by definition includes a (specific) AI detector software, it requires it to work.
Several startups, existing tech giants, AI companies, and university research departments have tried. There are literally millions on the line. All they’ve managed to do is get students incorrectly suspended from school, misidentify the US Constitution as AI output, and get a network really good at identifying training data and absolutely useless at identifying real world data.
Note that I said that this is probably impossible, only because we’ve never done it before and the experiments undertaken so far by some of the most brilliant people in the world have yielded useless results. I could be wrong. But the evidence so far seems to indicate otherwise.
Right, thanks for the corrections.
In case of GAN, it’s stupidly simple why AI detection does not take off. It can only be half a cycle ahead (or behind), at any time.
Better AI detectors train better AI generators. So while technically for a brief moment in time the advantage exists, the gap is immediately closed again by the other side; they train in tandem.
This does not tell us anything about non-GAN though, I think. And most AI is not GAN, right?
True, at least currently. Image generators are mostly diffusion models, and LLMs are largely GPTs.
I don’t know… My computer can do crazy math like 13+64 and other impossible calculations like that.
Wow, I got a 12/20. I thought I would get less. I’m scared for the future of artists
Why? A lot of artists have adopted AI and use it as just another tool.
I’m sure artists can use it as another tool, but the problem comes when companies think they can get away with just using ai. Also, the ai has been trained using artwork without any artist permission
Yeah and I’m sure there are some artists out there making really novel work using AI as a tool, but a lot of amateur artists made the bulk of their money doing things that AI can just do for basically nothing now.
If I want a character commission for my DnD character, I can get something really fucking excellent in an afternoon of playing around with Stable Diffusion, and that’s without any real expertise in AI tools or “prompt engineering”. Same with portraits of family, pets, friends, etc - and of course the smutty stuff that has always been the real money maker for low level amateur artists
Those types of artists are already really suffering as a result of the tools available now, and it’s only going to get worse as these tools get easier and cheaper to use
Agreed. And I want to go a bit further to talk about why else this might be bad.
Some people believe that losing jobs to AI is fine, because it means society is more efficient; and that it gives people time to do other things. But I think there are a few major flaws in that argument. For a lot of people, their sense of purpose and sense of self, and their source of happiness comes from their art and their creativity. We can say “they can just do something else” but we’ve basically just making their lives worse. Instead of being paid and valued for making art; they can get paid for serving coffee or something… and perhaps not have as strong of a sense of purpose or happiness. Even if we somehow eliminate inequality, and give everyone huge amount of free-time instead of works, it’s still not clear that we’ve made it better. We just get people mindlessly scrolling on social media instead of creating something.
That’s just one angle. Another angle is that by removing the kind of jobs that AI can do well, we remove the rungs on the ladder that people have been using to climb to other higher-level skills. An artist (or writer, or programmer, or whatever else), might start out by doing basic tasks that an AI can do easily; and then build their skills to later tackle more complex and difficult things. But if the AI just takes away all opportunities that are based on those basic tasks, then people then won’t have those opportunities to build their skills.
So… if we put too much emphasis on speed & cost & convenience, we may accidentally find ourselves in a world where people are generally less happy, and less skilled, and struggle to find a sense of value or purpose. But on the plus side, it will be really easy to make a picture of a centaur girl or whatever.
This is basically just a “we shouldn’t have cars because it would be bad for carriage and buggy whip makers, and they’d be less happy if they had to find other work” argument.
The short version is that the people upset about this stuff have also benefitted immensely from lots of other jobs being automated away and thought they were immune until the first image generating models hit the scene. Now they fear the same thing that happened to a lot of manufacturing jobs, except it’s a problem now because white collar work and creatives are supposed to be immune.
I don’t think it is as simple as that, but I certainly do see your point of view. And I’d probably agree if I didn’t feel like society is accelerating towards a very problematic future. (The problems I’m thinking of are not directly related to what we’re talking about here; but I just see this as part of what it might look like to start changing direction).
I’d just advise that we think about what the end-goal is meant to look like. What are we hoping for here. What does it mean to have a good life. In many stories and visions of the future, people seem to envision utopia as people spending their time on artistic and creative pursuits; as in, that’s the thing we were meant to free out time for. So the automate that part away might be a mistake. We’re likely to just end up freeing time for something destructive instead.
This is a capitalism problem.
I consider this a problem of capitalism, not synthetic art.
And that’s a fair perspective, but it doesn’t really change the core issue
The training data containing non licensed artwork is an extremely short term problem.
Within even a few years that problem will literally be moot.
Huge data sets are being made right now explicitly to get around this problem. And ai trained on other AI to the point that original sources no longer are impactful enough to matter.
At a point the training data becomes so generic and intermixed that it’s indistinguishable from humans trained on other humans. At which point you no longer have any legal issues since if you deem it still unallowed at that point you have to ban art schools and art teachers functionally. Since ai learns the same way we do.
The true proplem is just that the training data is too narrow and very clearly copies large chunks from existing artists instead of copying techniques and styles like a human does. Which also is solvable. :/
Which is an issue if those artists want to copyright their work. So far the US has maintained that AI generated art is not subject to copyright protection.
I wonder how this will play out for works that are only partially done by AI
For instance, I know some authors are using chatGPT to help brainstorm plot and dialog, so at what % of AI use is a book “human made” vs “AI made”? If I use chatGPT to write half my dialog, is it still my work? What if I heavily edit the dialog I given, while still keeping it mostly intact?
Its definetely going to be interesting to watch how this all unfolds, but yeah I’d definitely be at least nervous if I made my living making art right now
Tough to say, but as an artist/writer myself, I’d still be in charge of what I want for my material. An artist knows what works and what doesn’t.
I used ChatGPT to give me a list of character names based on the description I gave it. I usually select one from dozens of choices, oftentimes mixing and matching, or giving more information for a new list. Someone else may not care and pick the first name they see.
Same goes with plot and dialogue. An artist will go back and forth with the A.I. to make improvements and decisions… whereas a non-artist might not know which one to pick and let A.I. do most of the work.
Then yes, that all might come down to a certain percentage of work, like 50% or more as an example. An artist will want their own voice to be shown so they’ll have a higher percentage of their work included, whereas a non-artist won’t care and just try to sell A.I. work as their own. The artist will have more say for copyright. Proving it will be difficult however… as teachers have found when grading students papers. Artists may need to keep a lot of notes during the creative process.
Only if it’s 100% synth art. What about partial? We don’t know.
As with other AI-enhanced jobs, that probably still means less jobs in the long run.
Now one artist can make more art in the same time, or produce different styles which previously had required different artists.
Having used stable diffusion quite a bit, I suspect the data set here is using only the most difficult to distinguish photos. Most results are nowhere near as convincing as these. Notice the lack of hands. Still, this establishes that AI is capable of creating art that most people can’t tell apart from human made art, albeit with some trial and error and a lot of duds.
Idk if I’d agree that cherry picking images has any negative impact on the validity of the results - when people are creating an AI generated image, particularly if they intend to deceive, they’ll keep generating images until they get one that’s convincing
At least when I use SD, I generally generate 3-5 images for each prompt, often regenerating several times with small tweaks to the prompt until I get something I’m satisfied with.
Whether or not humans can recognize the worst efforts of these AI image generators is more or less irrelevant, because only the laziest deceivers will be using the really obviously wonky images, rather than cherry picking
AI is only good at a subset of all possible images. If you have images with multiple people, real world products, text, hands interacting with stuff, unusual posing, etc. it becomes far more likely that artifacts slip in, often times huge ones that are very easy to spot. For example even DALLE-3 can’t generate a realistic looking N64. It will generate something that looks very N64’ish and gets the overall shape right, but is wrong in all the little details, the logo is distorted, the ports have the wrong shape, etc.
If you spend a lot of time inpainting and manually adjusting things, you can get rid of some of the artifacts, but at that point you aren’t really AI generating images anymore, but just using AI as source for photoshopping. If you just using AI and pick the best images, you will end up with a collection of images that all look very AI’ish, since they will all feature very similar framing, posing, layout, etc. Even so no individual image might not look suspicious by themselves, when you have a large number of them they always end up looking very similar, as they don’t have the diversity that human made images have and don’t have the temporal consistency.
These images were fun, but we can’t draw any conclusions from it. They were clearly chosen to be hard to distinguish. It’s like picking 20 images of androgynous looking people and then asking everyone to identify them as women or men. The fact that success rate will be near 50% says nothing about the general skill of identifying gender.
I have it on very good authority from some very confident people that all ai art is garbage and easy to identify. So this is an excellent dataset to validate my priors.
Curious which man made image was most likely to be classified as ai generated
and
About 20% got those correct as human-made.
That’s the same image twice?
Thanks. Fixed.
My first impression was “AI” when I saw them, but I figured an AI would have put buildings on the road in the town and the 2nd one was weird but that parts fit together well enough.
I think it’s because of the shadow on the ground being impossible
I guessed it to be ai generated, because
- the horses are very artsy, but undefined
- the sky is easy to generate for ai
- the landscape as well. There is simply not a lot the ai can do wrong to make a landscape clearly fake looking
- undefined city from afar is like the one thing ai is seriously good at.
Yeah, but the bridge is correctly over the river and the buildings aren’t really merged. Tough though.
The second one got me tho
deleted by creator
Sketches are especially hard to tell apart because even humans put in extra lines and add embellishments here and there. I’m not surprised more than 70% of participants weren’t able to tell that one was generated.
Thank you so much for sharing the results. Very interesting to see the outcome after participating in the survey.
Out of interest: do you know how many participants came from Lemmy compared to other platforms?
No idea, but I would assume most results are from here since Lemmy is where I got the most attention and feedback.
I’m found the survey through tumblr, i expect there’s quite a few from there.
Oh nice, do you have a link for where it was posted?
i’ll see if i can find it, but my dashboard hits 99+ notification in about six hours…













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}