
2·
1 year agoNot necessarily, you still need backups or snapshots especially on home directory in case software have a nasty bug like deleting your data.
Not necessarily, you still need backups or snapshots especially on home directory in case software have a nasty bug like deleting your data.
Yup and I am getting sick of hearing this even on Arch Linux. Like, mofo, you could literally run a snapshot or backup before upgrading, don’t blame us if you’re yoloing your god damn computer. Windows have exactly the same problem too and this is why we have backups. Christ.
On my Arch Linux Install, I literally have a Pacman Hook that would forcibly run backup and verify the said backup before doing a system-wide update.

That one was an old documentation that some of the Chinese folks actually document a lot of quirks related to X11 protocol. I paid about $6000 for translator to work on translating that doc to English and I use it to build my own GUI Toolkit on Linux that I still use to this day.
How it really works:
mpf_t temperature;
It’s arbitrary sized floating precision number provided in LibGMP and you can find more information about mpf_t here.

Oof, sorry. :( I had hoped that they sorted it out by then…
Maybe try installing swiftshader?

Lol, that one way to put it. Basically a language convergence, not a bad thing to be honest.
Yeah, MLIR is more or less an “IR with Dialects”, a lot of IR language spec share a lot in common with one another, so MLIR try to standardize that similarity between IR. Because of that feature, it reduce amount of IR code that developer have to worry about and they can progressively expand the available dialects for MLIR as they develop a compiler like IREE.
Yup, been writing a new shader language to replace GLSL and HLSL for Vulkan Compute purposed, but I eventually switch from SPIR-V IR to MLIR and use IREE Compiler which accepts the MLIR and compile it to any of CUDA, ROCm, SPIR-V and so forth.
It’s one of the project that I’ve been working on to outright replace Pytorch/Tensorflow and ban those two framework from my office forever. I got fed up not knowing how much exactly do I need in memory allocation, computational cost, and so forth when running or training neural net models. Plus I want an easier way to split the model across lower-end GPU too that doesn’t rely on Nvidia-only GPU for CUDA code. I also wanted to have SPIR-V as a fallback compute kernel, because if CUDA/ROCm is too new for GPU, you’re SOL, but if you have SPIR-V, chances are, any GPU made in the last 10 years that have a Vulkan Driver, would likely be supported.
One of the biggest plus with MLIR is that you are also future proofing your code, because that code could feasibly be recompiled for new devices like Neural Net accelerator cards, ASIC, FPGA, and so forth.
Very nice, I was basically forking off Python Lark and rewriting it in C language, with some adjustments to Earley Parser in an experiment to parallelize the processing in Vulkan Compute.
I agree on avoiding on the idea of avoiding having to make your own parser generator, this is precisely what I’m doing and it’s hell. I assumed that you probably want to pick up some understanding on how parser differs when it come to writing grammars. As for ease of use and requiring the least understanding, using something like Earley parser is probably the easiest, it would be slower than other parser algorithms, but it could handle ambiguous grammars making it ideal for first timers to learn how to write a programming language.
Yep, and if open source licensing could be revoked on a whim, you can imagine the chaos that ensued. That would be my understanding as well, old version that have MPL license is perfectly fine to fork off, newer version might not be as it is under a different license. One of the reason why I liked Apache License is that it have make it explicitly clear that it’s irrevocable whereas MPL it is operating on an assumption that it’s not revocable. The most fundamental problem with the legal system in USA is that no law is “set in stone” and leaving things to assumption is open to reinterpretation by the judge who may have sided against you. (Hell, Google vs Oracle on Copyrighted API is still on case-to-case basis, so take it as you will.)
Disclaimer: I am not a lawyer. I just share what I learned from Legal Eagle youtube and few other sources.
I definitely recommends that you start learning about the LL(k), LALR, and perhaps even Earley Parser algorithms. I am assuming you have picked up a little bit on LL(1) parser and some basic lexer, so mastering the parser algorithms are basically the next stop for you.
Once you get the grasp of those things, you are well on your way to designing a programming language.

I concur, there was a few problems that might come up on various platforms like Windows not implementing C11 standard threads and other stuff, you would instead use TinyCThread library that works like a polyfill.
All problems and challenges are workable, if the problem with Debian is out of date library, you could set up CI/CD for release build that rebuild your software when update occurs and static link the updated dependencies.
Back to your point, if they didn’t design their code and architecture to be multiplatform like in C, they need to re-evaluate their design decisions.
I would spend it on language translation basically, paying someone to translate international documentations on things that aren’t documented in USA no matter where you look.

It’s incredibly difficult task to master/learn an old technology or an old concept that aren’t documented well. For an example, parser algorithms are very well known for being too verbose and unnecessarily over-complicated in documentation, if you ask anyone you know in the programming community, for the next 100 people, they wouldn’t know how to implement LALR parser or Earley parser even if they graduate from university with a computer science degree.
One of the way I use to learn a concept is writing a full manual of it in LaTeX in a way that I am explaining every single aspect of it to a layman and how it can be implemented in every way as well as providing examples in C code forms. It’s a bit interesting that you sometime learn better by trying to teach it to a made up audience when writing a manual.
Example page from a book I’m current writing in rough draft:


I think it’s asinine to ask the developer who contribute to your project, literally taking the time of the day writing the code and submit PR to your project, to pay money to you.
I wouldn’t even bother contributing to the project at that point.
This is not the first time it happens with Dotnet Open Source packages, there are some pretty funky things going on namely:
Imagesharp (They re-license from Apache 2 to something like Community/Commercial licenses and threw a huge fit over it)
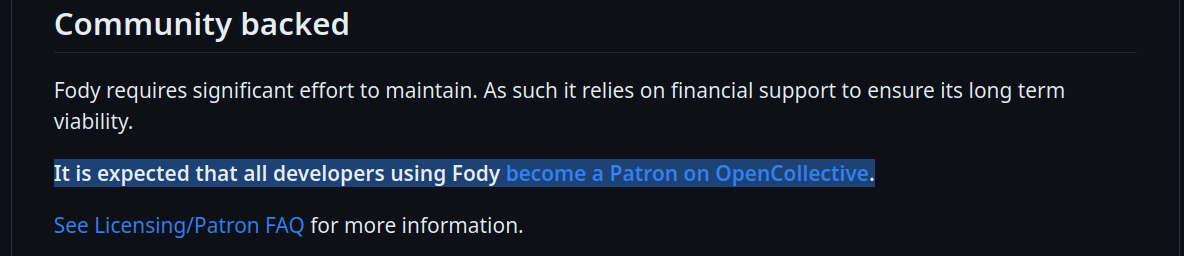
Fody (It expects the software contributors of Fody to be a patron.)


Sure until you can’t with flatpak. Flatpak does not safeguard against system binaries and there are always risks associated with that.
Honestly I think I am going to move on from Programming.dev, it’s filled with script kiddie like you. Good lord.
Fuck y’all. Good evening.