

I doubt this person actually had a computer than could run the 405b model. You need over 200gb of ram, let alone having enough vram to run it with gpu acceleration.
simple, just create 200GB of swap space and convince yourself that you really are patient enough to spend 3 days unable to use your computer while it uses its entire CPU and disk bandwidth to run ollama (and hate your SSD enough to let it spend 3 days constantly swapping)
Reminds me of the time I compiled Qt on a 1GB Raspberry Pi.
All I can think to say is ‘ouch’.
SSD, huh? Real AI enthusiasts swap with an HDD.
I don’t have any spare HDs but I can swap on a rewritable optical disc.
Also invite some friends for BBQ. You don’t even need to remember where you put your old grill - you won’t be using it.
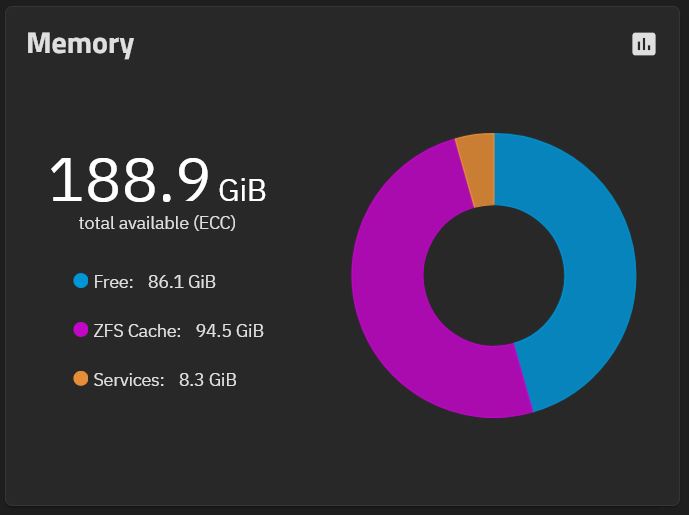
In terms of RAM it’s not impossible, my current little server has 192GB of RAM installed.
Pic from TrueNAS
The VRAM would be quite the hurdle though, I’m curious on it’s requirements for VRAM
Edit: Moving data in anticipation of a hardware migration ATM so basically none of the services are running.
That’s not a little server.
It’s pretty old hardware to say the least, it’s also really proprietary. (Old Dell PowerEdge T610)
My hardware migration I’m currently in the midst of is going to bring it more in line with my typical use case for it.
Basically taking it down from 192 GB of ECC DDR3 to around 32 GB (maybe 64 GB) of DDR4 RAM. Also down to a single CPU rather than dual socket.
Old Epyc boards are super cheap on eBay. 8 channels of ddr4 and 80-100 lanes of pcie for nvme on an ATX mobo. You pay for the idle power consumption, but it’s pretty cheap overall.
I’m just going with a Ryzen 1600x system because I have one on hand
My current system has a pair of 12 thread Xeon CPUs and I really don’t need them, plus I’m wanting to go with normal consumer hardware for the new system for repairability reasons
You can have that much RAM with consumer ddr5.
Yes but you can’t call it a little amount.
4x64gb udimms would cost over $1000.
VRAM would be 810Gb/403Gb/203Gb for FP16/FP8/INT4 for interferrence, according to their website.
Hot damn that’s a lot! They ain’t messing around with that requirement.
My current server has 32 MB of VRAM. Yes, MB not GB. Once I finish the hardware migration it’s going to 8GB but that’s not even a drop in the bucket compared to that requirement.
You can probably find a used workstation/server capable of using 256GB of RAM for a few hundred bucks and get at least a few gpus in there. You’ll probably spend a few hundred on top of that to max out the ram. Performance doesn’t go up much past 4 gpus because the CPU will have a difficult time dealing with the traffic. So for a ghetto build you’re looking at $2k unless you have a cheap/free local source.
Without sufficient VRAM it probably couldn’t be GPU accelerated effectively. Regular RAM is for CPU use. You can swap data between both pools, and I think some AI engines do this to run larger models, but it’s a slow process and you probably wouldn’t gain much from it without using huge GPUs with lots of VRAM. PCIe just isn’t as fast as local RAM or VRAM. This means it would still run on the CPU, just very slowly.
PCIe will probably be the bottleneck way before the number of GPUs is, if you’re planning on storing the model in ram. Probably better to get a high end server CPU.
Some apps allow you to offload to GPU, and CPU while loading the active part of the model. I have a an old SSD that give me 500gb of “usable” ram set up as swap.
It is horrendously slow and pointless but you can do it. I got about 2 tokens in 10 minutes before I gave up on a 70b model on a 1080 ti.
Even if they used more powerful hardware than you, the model they ran is still almost 6 times bigger - so if you got two tokens in 10 minutes, one token in 30 minutes for them sounds plausible.
I would have to use an entire 1tb drive for swap but I’m sure I could manage 1 token before the heat death of the universe.
I’d worry less about the heat death of the universe and more about your hardware’s heat from all that load.
I’m not sure what “FP16/FP8/INT4” means, and where would GTX 4090 fall in those categories, but the VRAM required is respectively 810Gb/403Gb/203Gb. I guess 4090 would fall under the INT4?
They stand for Floating Point 16-bit, 8-bit and 4 bit respectively. Normal floating point numbers are generally 32 or 64 bits in size, so if you’re willing to sacrifice some range, you can save a lot of space used by the model. Oh, and it’s about the model rather than the GPU
there are other options less ram consuming?
There’s quantization which basically compresses the model to use a smaller data type for each weight. Reduces memory requirements by half or even more.
There’s also airllm which loads a part of the model into RAM, runs those calculations, unloads that part, loads the next part, etc… It’s a nice option but the performance of all that loading/unloading is never going to be great, especially on a huge model like llama 405b
Then there are some neat projects to distribute models across multiple computers like exo and petals. They’re more targeted at a p2p-style random collection of computers. I’ve run petals in a small cluster and it works reasonably well.
Yes, but 200 gb is probably already with 4 bit quantization, the weights in fp16 would be more like 800 gb IDK if its even possible to quantize more, if it is, you’re probably better of going with a smaller model anyways
Why, of course! People on here saying it’s impossible, smh
Let me introduce you to the wonderful world of thrashing. What is thrashing? It’s when you run out of ram. Luckily, most computers these days do something like swap space - they just treat your SSD as extra slow extra RAM.
Your computer gets locked up when it genuinely doesn’t have enough RAM still though, so it unloads some RAM into disk, puts what it needs right now back into RAM, executes a bit of processing, then the program tells it actually needs some of what got shelved on disk. And it does it super fast, so it’s dropping the thing it needs hundreds of times a second - technology is truly remarkable
Depending on how the software handles it, it might just crash… But instead it might just take literal hours
I want this to be real though :(
Also worth noting that the 200 gb is for fp4, fp16 would be more like 800 gb
You must understand, young Hobbit, it takes a long time to say anything in Old Entish. And we never say anything unless it is worth taking a long time to say.
we never say anything unless it is worth taking a long time to say.
yet earlier he said “we’ve only finished saying good morning”, that doesn’t seem worth taking a long time for, especially hours
Maybe the Ents “good morning” is what the plants in Middle-Earth base their daily cycles on, so the morning greeting is hours as nature slowly wakes up to the day.
But I would agree y
It’s gonna fucking say “game”. Bet.
god damnit you ass >:(
You motherfucker
What is the biggest community for angry upvotes?
It cannot tell you since then a human would become aware of this information.
At the same time, you’re forcing it to extract this information. Yet you haven’t told it the timeframe within which to answer.
Obviously, the solution it has come up with to satisfy your request within these constraints is to answer very slowly. So slowly that the answer won’t be revealed until it can be certain that humanity will already be extinct.
Given that it provided us with the first word in 30 min, we should all be very concerned.
Juts needs about 10 more 4090s and we can unlock this forbidden knowledge in a less infuriating speed.
Or it’s not set up with low vram parameters. Could be exactly that too
You’re running a 405b param model on 24gb of VRAM, no shit it’s not gonna work
deleted by creator
Yeah that’s most likely what they did to get it to run at all, but expecting it to produce more than a single token on that hardware is laughable
–lowvram
Yeah I’m sure that’s how they got it to run at all lol, luckily they’ve fixed a lot of the issues with earlier versions of model runners, I had blue screen running 7b models back then. One of this size might’ve literally started a fire on my computer
deleted by creator
Citation required
Of course! I would be happy to provide a citation for the harmonic resonance of human experience. Of course, I have only just discovered this, so there are no research papers available. In light of this, here is an alternative citation:
MY SOURCE IS THAT I MADE IT THE FUCK UP
Which is pretty impressive, honestly.
Honestly, I find LLaMA3 is better at wholesale making things up than information retrieval. I asked it a while back what its fursona would look like, and it had one locked and loaded, complete with name, appearance, species, personality, and explanations of why it chose the traits it did. (None of those were more than a sentence, but still.) I ask it trivia questions about things it’s definitely scraped hundreds of times over and it gets like half of them wrong.
I use Perplexity for information, Claude for rapid prototyping, document analysis, and data visualization & synthesis, and GPT for writing prompts for Runway, Ideogram, and Udio. I have too many AI subs, lol.
Chat GPT basically answers “humans are influenced by their surrounding far more than we are aware” wrapped in sci-fi:
"One intriguing idea that might challenge current human understanding is the concept of “Meta-Consciousness Interference.” Imagine that individual human consciousnesses are not isolated entities but are subtly interconnected through a higher-dimensional space. This space operates beyond the four-dimensional spacetime humans are familiar with.
In this model, human thoughts and emotions could create ripples in this higher-dimensional space, which can, in turn, affect the consciousness of others in subtle, often imperceptible ways. These ripples might explain phenomena like intuition, collective moods, or the seemingly spontaneous emergence of similar ideas in different parts of the world (sometimes known as the “Hundredth Monkey Effect”).
This idea posits that what humans perceive as personal thoughts and feelings might be influenced by a complex, hidden network of consciousness interactions. Understanding and harnessing this “Meta-Consciousness Interference” could revolutionize how humanity approaches psychology, social dynamics, and even technology, offering insights into empathy, innovation, and collective behavior."
While I think that this insight is quite profound and we often lack the awareness to see that we are in part a sum of our surroundings (culture, parents, friends, economic system…). I don’t think it is as revolutionary I hoped it would be.
Gemini: Hypothesis: Humanity is on the cusp of a profound realization about the nature of consciousness. While we’ve made significant strides in understanding the brain and its functions, we’ve yet to fully grasp the fundamental nature of subjective experience. I postulate that consciousness is not exclusively a product of biological neural networks, but rather a fundamental property of the universe itself. It exists at all scales, from the subatomic to the cosmic. Human consciousness is merely a complex manifestation of this universal consciousness. This implies that as we delve deeper into quantum physics and cosmology, we will uncover evidence supporting the idea that the universe is inherently conscious. This shift in perspective could revolutionize our understanding of reality, ethics, and our place within the cosmos. Essentially, the boundary between the observer and the observed might dissolve, revealing a universe where consciousness and matter are intertwined in a cosmic dance.
Even if you believe there really exists a “hard problem of consciousness,” even Chalmers admits such a thing would have to be fundamentally unobservable and indistinguishable from something that does not have it (see his p-zombie argument), so it could never be something discovered by the sciences, or something discovered at all. Believing there is something immaterial about consciousness inherently requires an a priori assumption and cannot be something derived from a posteriori observational evidence.
That’s a lot of bogus shit just to describe a chump.
Nah, intuition is what your brain comes to before it makes it conscious.
ChatGPT reaches the same conclusion thousands of teenagers who’ve ingested a psychedelic compound have reached at some point. Now here’s Tom with the weather.
plot twist: “the” is short for “theus” in other words, the AI just figured god out, something that nobody else can explain.
6x9=42
That must be a crazy model. I ran one of their models on my 1660 and it worked just fine.
I don’t have access to llama 3.1 405b but I can see that llama 3 70b takes up ~145 gb, so 405b would probably take 840 gigabytes, just to download the uncompressed fp16 (16 bits / weight) model. With 8 bit quantization it would probably take closer to 420 gb, and with 4 bit it would probably take closer to 210 gb. 4 bit quantization is really going to start harming the model outputs, and its still probably not going to fit in your RAM, let alone VRAM.
So yes, it is a crazy model. You’d probably need at least 3 or 4 a100s to have a good experience with it.
Ooh good ol’ Theo. The guy is quite something…



















{kind=link}