

- cross-posted to:
- technology@lemmy.zip
- technology@lemmy.world
- cross-posted to:
- technology@lemmy.zip
- technology@lemmy.world
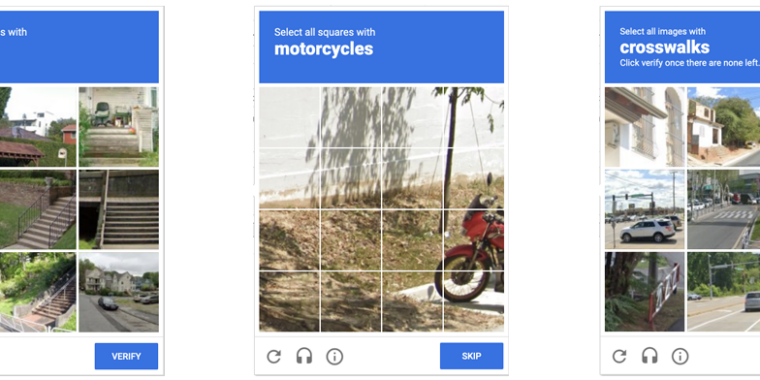
Anyone who has been surfing the web for a while is probably used to clicking through a CAPTCHA grid of street images, identifying everyday objects to prove that they’re a human and not an automated bot. Now, though, new research claims that locally run bots using specially trained image-recognition models can match human-level performance in this style of CAPTCHA, achieving a 100 percent success rate despite being decidedly not human.
ETH Zurich PhD student Andreas Plesner and his colleagues’ new research, available as a pre-print paper, focuses on Google’s ReCAPTCHA v2, which challenges users to identify which street images in a grid contain items like bicycles, crosswalks, mountains, stairs, or traffic lights. Google began phasing that system out years ago in favor of an “invisible” reCAPTCHA v3 that analyzes user interactions rather than offering an explicit challenge.
Despite this, the older reCAPTCHA v2 is still used by millions of websites. And even sites that use the updated reCAPTCHA v3 will sometimes use reCAPTCHA v2 as a fallback when the updated system gives a user a low “human” confidence rating.
You must log in or register to comment.
Need these bots as a browser addon now. When your using a VPN these things are the bane of your Internet browsing experience.
And I’ll be fucked if I can get them right first time round half the time!
Hmmm… do you float if we throw you in the water?
I don’t use a VPN and they are still highly problematic. I get stuck in a cycle, like with cloudflare.
https://addons.mozilla.org/en-GB/firefox/addon/buster-captcha-solver
it switches to the accessibility version of CAPTCHA and uses speech recognition to solve it.
I’ve never been able to get this one to work, it will say it can’t detect speech even though I can hear it being played.
for me it works most of the time, and I don’t hear the speech being played at all while it’s being solved. and it the rare cases when it doesn’t detect speech, requesting another puzzle usually fixes it.
So the robots are now more successful at proving they’re human than I am.
The inverted Turing test, it would seem.
Beep boop I am smarter than you… 🎵
Bleep bloop you seem to me dumb as rock… 🎼

I need a bot then. I click through 7-8 of those and still don’t pass.
What’s ironic is that the main purpose of reCAPTCHA v2 is to train ML models. That’s why they show you blurry images of things you might see in traffic.
AFAIK the way it works is that of the 9 images, something like 6 are images the system knows are True or False, and another 3 are ones it is being trained on. So, it shows you 9 images and says “tell me which images contain a motorcycle”. It uses the 6 it knows to determine whether or not to let you pass, and then uses your choices on the other 3 to train an ML model.
Because of this, it takes me forever to get past reCAPTCHA v2, because I think it’s my duty to mistrain it as much as possible.
You’re wasting your time. Your fingerprint is graded and discarded if you’re not reliable
At least it adds noise to the system. It’s better than the people who are happily training the AI.
I’m sure they use the reliability of your inputs for known images to determine whether to use your input to train unknown images.
That’s good, hopefully we will quit seeing them. Because I’ve gotten to the point if I see a captcha I just go to another site unless it’s something I’ve got to do.
deleted by creator
Apparently someone already did with this extension: https://github.com/dessant/buster
Ok, so can we get rid of them then? They’re fucking annoying and waste time
“bots trained on tests for years now able to pass them”
Mfw AI is better at proving they’re a human than I am
I need a bot because I get stuck in a loop of captchas
It’s the age old question, does the pole count as part of a traffic light?
Happy Cakeday! 🍰🎂
Then give me a FF addon that does these for me because I’m nowhere near that successful.
Here’s one that uses the audio challenge: https://addons.mozilla.org/en-US/firefox/addon/buster-captcha-solver/
. . . that’s because we’ve been using these images to train AI for years?
Google has. The Zürich university fella needed his own data classification monkeys.
From a UX perspective, those things are cancer.
Recaptcha 4.0… what do you think about this image…an image of a kid riding their bike without any protective gear on a freeway.
AI: a bike with a kid on it on a road. Perfectly fine.
Emotion provoking images sounds like an ingenious solution honestly
Well, that’s it, boys. We’ve gone full Blade Runner.
“Let me tell you about my mother…”
It’d be a bit unreliable, though. Not everyone has the same reaction to the same thing, nor do they express it in a similar way.
Someone might think a snake or a spider is cute, whereas another would want to incinerate it on the spot. A third might be concerned because they seem to be injured, etc.
Not to mention that image recognition/emotional analysis has been an ongoing field of research for some time. Making the link is not overly difficult.
Oh good we finally trained them enough. Can we please
get rid of captcha nowhave the next portion?So the bots can now train the bots. About time. Now f off Google with your nasty privacy destroying captcha








